在網(wǎng)絡安全的世界里,“后門攻擊”是個耳熟能詳?shù)脑~匯,那它究竟意味著什么呢?
想象一下,你購買了一套高級的智能門鎖,但賣家偷偷藏了一把備用鑰匙,等你安裝好后,他們就可以輕松地進入你的家——這就是后門攻擊的核心思想。攻擊者通過在正常軟件中嵌入惡意代碼,讓用戶在不知情的情況下打開了自家的大門。
GitHub作為全球最大的開源代碼托管平臺,承載著數(shù)以萬計的項目,是后門攻擊的重災區(qū)。而對于AI模型,也有一個類似的托管平臺——Hugging Face,這里同樣托管著海量的模型,供開發(fā)者免費下載使用。那么,AI模型是否也會遭遇同樣的后門攻擊呢?
答案是肯定的。就像惡意代碼可以悄悄潛入軟件一樣,惡意AI模型也能以同樣的方式侵入我們的系統(tǒng)。今天,我們就來揭開序列化后門攻擊的秘密面紗。
AI模型的后門攻擊有很多種,我們今天只講序列化后門攻擊。
首先,我們需要了解AI模型是如何保存和加載的。簡單來說,AI模型通過序列化技術進行存儲,這意味著將模型的狀態(tài)轉(zhuǎn)化為一種易于保存的形式。你可以把它想象成拆解一個樂高模型的過程:將完整的模型拆分成一個個小零件,然后小心地裝進一個盒子里,并附上組裝說明書。這就是序列化的過程。當你的朋友收到這個樂高模型包裹后,他們會按照說明書上的步驟,將這些零件重新組合起來,恢復成原來的模型。這個過程就是反序列化。
現(xiàn)在,想象一下,你在郵寄包裹時悄悄塞入了一個可以遠程控制的小攝像頭,并在組裝說明書中加入了這樣一行字:“組裝完成后,請按下按鈕開啟攝像頭。”雖然這對組裝樂高沒有任何幫助,但卻讓你有了窺視朋友的能力。這個攝像頭就是所謂的后門,而模型后門攻擊的目標就是讓你的朋友遵照說明,無意中啟動這個攝像頭。
AI模型可以以多種格式存儲,但在眾多存儲格式中,有三種特別值得關注,因為它們面臨著較高的序列化攻擊風險:Pickle及其變種、SavedModel以及H5格式。
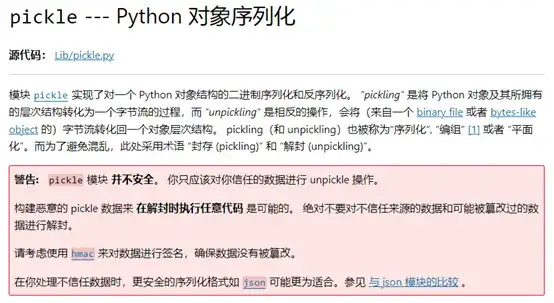
Pickle是Python的內(nèi)置模塊,實現(xiàn)了對一個Python對象結構的二進制序列化和反序列化。它的序列化漏洞由來已久,其官方文檔開頭便有對其風險的警告:
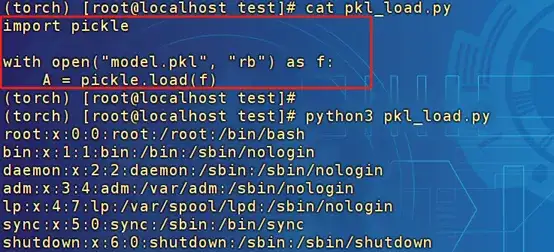
Pickle模塊的風險在于反序列化時,__reduce__方法會被調(diào)用。這就意味著,只要在序列化之前重寫__reduce__方法,并在里面嵌入執(zhí)行操作系統(tǒng)命令的邏輯,就能在加載模型時觸發(fā)這些命令,實現(xiàn)遠程代碼執(zhí)行(RCE)攻擊。例如,假設你加載了一個被惡意修改過的模型,其中的__reduce__方法被重寫為執(zhí)行“cat /etc/passwd”命令:
只是簡單地調(diào)用了Pickle.load,在反序列化時便執(zhí)行了命令。
在與AI相關的框架中,Numpy和PyTorch的save函數(shù)都是使用的Pickle模塊,因此也可以使用同樣的方式來加載后門。
SavedModel是TensorFlow提供的一種模型存儲格式,它不僅保存了模型的所有參數(shù),還包括了完整的計算圖。盡管大多數(shù)TensorFlow操作專注于機器學習計算,但涉及文件操作的功能如io.read_file和io.write_file卻為攻擊者打開了序列化攻擊的大門。
io.read_file可以被濫用去讀取系統(tǒng)中的敏感文件,而io.write_file的風險更大,因為它可以用來寫入任意文件。以Linux系統(tǒng)為例,攻擊者可以利用它往用戶的家目錄.ssh/authorized_keys文件中寫入SSH公鑰,從而實現(xiàn)免密碼登錄操作系統(tǒng)。此外,還可以往cron文件中添加計劃任務,自動下載惡意程序并在后臺執(zhí)行。
那么,如何讓這些文件讀寫操作得以執(zhí)行呢?這里的關鍵是利用TensorFlow的call函數(shù)。在TensorFlow中,無法直接在加載模型時執(zhí)行反序列化攻擊,而是在調(diào)用模型時才能觸發(fā)。每當模型被調(diào)用時,都會執(zhí)行一次call函數(shù),而 build 函數(shù)則會在call函數(shù)首次執(zhí)行時被調(diào)用一次。因此,只需將文件相關的操作寫入call或build函數(shù)中,就可以在加載模型時實現(xiàn)文件的讀寫。
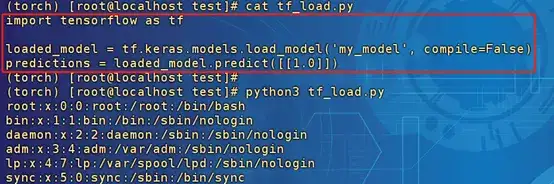
以下是一個在call函數(shù)里面實現(xiàn)了“io.read_file('/etc/passwd')”操作的模型加載和調(diào)用過程的例子:
在調(diào)用模型時進行預測時,io.read_file被執(zhí)行了,且并不會影響predict的效果。
Keras是少數(shù)幾個原生支持將模型序列化為HDF5格式的機器學習框架之一。HDF5作為一種在學術界和研究領域廣泛流行的通用數(shù)據(jù)序列化格式,通常被認為是安全的。然而,Keras的Lambda層卻為攻擊者打開了一扇后門。
Lambda層的設計初衷是為了在數(shù)據(jù)傳遞給機器學習模型之前進行預處理或后處理操作。然而,它允許執(zhí)行任意代碼的特點,卻成為了潛在的攻擊點。攻擊者可以利用Lambda層來執(zhí)行操作系統(tǒng)命令,從而實現(xiàn)遠程代碼執(zhí)行(RCE)攻擊。
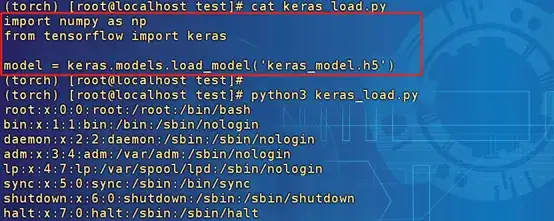
以下模型在Lambda層實現(xiàn)了“os.system('cat /etc/passwd')”操作,加載模型:
模型在加載時執(zhí)行了Lambda層的命令。
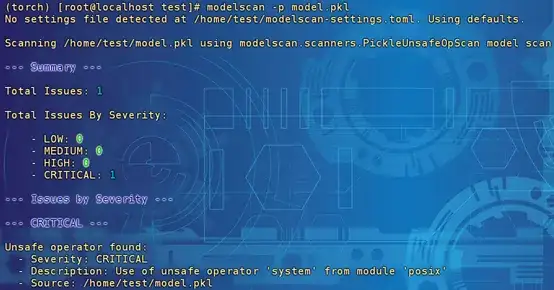
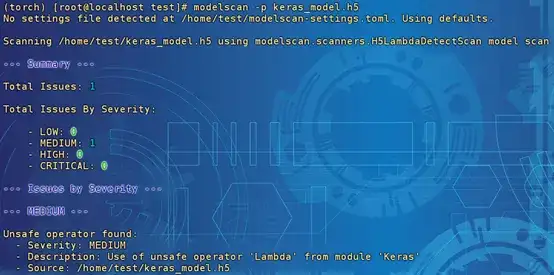
說完了模型后門植入的方法,接下來我們來看看如何檢測這些潛在的威脅。幸運得是,現(xiàn)在已經(jīng)有一些開源的掃描工具可以幫助我們評估模型的安全性。例如,Protect AI的ModelScan工具就是其中之一。讓我們一起探索這款工具在檢測上述三種序列化后門方面的表現(xiàn)吧!
檢測結果為嚴重風險,描述信息為使用來自模塊“posix”的不安全運算符“system”。
檢測結果為高風險,描述信息為使用模塊“Tensorflow”中不安全的運算符“ReadFile”。
檢測結果為中風險,描述信息為使用模塊“Keras”中不安全的運算符“Lambda”。此處只能檢測存在Lambda層,沒辦法檢測到具體的操作了。
使用工具進行檢測只是保障模型安全的一個方面,更重要的是始終保持警惕,只使用來自可信來源的模型。畢竟,預防勝于治療,確保模型的安全性從源頭抓起才是王道。
昂楷科技磐石研究院作為專注于技術研究的核心部門,多年來深耕數(shù)據(jù)安全領域,緊跟數(shù)據(jù)安全發(fā)展的前沿趨勢,匯聚了一支技術實力雄厚的專業(yè)團隊。隨著人工智能技術的迅猛發(fā)展,我們積極投身于AI安全領域的探索,致力于深入研究AI攻擊與防御技術,為推動AI安全的發(fā)展貢獻力量。
展望未來,我們將不斷強化自身的技術實力,為AI安全領域帶來創(chuàng)新性的解決方案。我們的安全產(chǎn)品將逐步推出AI領域的專業(yè)能力,實現(xiàn)對AI攻擊的有效檢測、監(jiān)測與防御,為用戶提供全方位的安全保障。